国民生活基礎調査匿名データ 解析実習を行いました(2021年度)
国民生活基礎調査匿名データ 解析実習を行いました(2021年度)
京大SPHの講義「健康情報学II」にて、国民生活基礎調査匿名データの解析実習を行いました。匿名データとは、行政機関等が統計法に基づいて実施した統計調査によって集められた調査票情報を、特定の個人又は法人その他の団体の識別ができないように加工したものです。学術研究及び教育の発展に資すると認められる場合は、一般の方も、利用することができます。今回は、教育目的として、厚生労働省に申出を行い、健康情報学IIにて、匿名データを利用した解析実習を行いました。

【講義名】
・健康情報学II(科目責任者 健康情報学・高橋由光)
【日時・場所】
・2021/12/24(金)、2022/1/7(金)、2/4(金) いずれも13:15-16:30
・京大医学部構内G棟3F演習室
【教材】
講義資料ハンズオンのPDFは下記をクリック
こちら(2020年度資料)
【概要】
・統計法および国連の公的統計の基本原則を中心に、公的統計データの二次的利用の規制の必要性および推進のバランス、調査対象の秘密保護について講義を行った。
・国民生活基礎調査(平成22年)匿名データB(世帯票・健康票・所得票・貯蓄票)を用いて、調査票、データレイアウト及び符号表の理解、csvファイルの読込、JMPを用いた記述統計・ロジスティック回帰分析等を行った。
・COVID-19感染予防のため、受講者を3グループに分け、同内容を3回実施した(1名につきスタンドアロンPC 1台)。
【参加人数】
・18名(教員1名、ティーチングアシスタント(TA)1名含む)
【参考情報】
厚生労働省 匿名データの提供について
http://www.mhlw.go.jp/toukei/itaku/tokumei.html
Shibuya, et al. BMJ. 2002 Jan 5;324:16.
https://pubmed.ncbi.nlm.nih.gov/11777798/
京大SPHウェブページ 国民生活基礎調査匿名データ 解析実習を行いました(2020年度)
https://sph.med.kyoto-u.ac.jp/news/5927/
【参加者の声】
・このようなデータを扱うのも、JMPを使うのも初めてでしたがとても分かりやすかったです。実際のデータを扱うことで、何を解析して何がわかるのかということが具体的に理解できました。
・ご講義ありがとうございました。少人数で、とても分かりやすい資料+必要時に適宜サポートいただけたことで大きく躓くことなく実習させていただくことができました。まだまだ統計ソフト(JMP)に慣れていない中ですが、興味深さを感じながら進めることができました。実習の中では解析の手順を中心に教えていただきましたが、実際に厚労省からデータを頂戴し、解析ができる状態に持っていくまでのプロセスが非常に大変であり重要でもあると感じました。実際に自分で手を動かして一つひとつ作業をしてみることで、これまではあくまで「結果」として表示されたものを見て考えたり、資料として参照していた統計データを、自分なりの視点で0から作ることができるということを体感できました。聞いてはいてもいまいち実感につながっていなかった「データベース解析」が、今までより少し自分事になりました。ありがとうございました。
・ありがとうございました。新しいことをたくさん学ばせていただきました。高橋先生が配布してくださった資料がとても分かりやすく、理解が深まりました。ダミー変数の設定のことも、詳しく教えていただいて、よく理解することができました。分析に至るまでに、きちっとデータを整えていく過程が楽しかったです。TAさんもとても丁寧に教えてくださって、安心して学ぶことができました。ありがとうございました。
・高橋先生に作成頂いたシラバスに従えば、ド素人でもBMJ論文が再現出来てしまいますが、実際に国のデータに触れる機会というのはなかなかないので、今回のようにJMPを使ってデータ解析ができたのは、大変貴重な機会であり、勉強になりました。TAさんにも大変お世話になりました。ありがとうございました。
・It is really interesting to have practical experience in data analysis (especially this huge volume of data and categories). It is fair to say that the most time-consuming section today was the preparation for analysis. I took a long time for data categorization and integration, carefully and discreetly, to avoid system errors (errors are annoying anyway). But it is quite cool that after this exhausting preparation, the analysis itself was very quick and smooth, thanks to JMP of course. In a word, it is great for me to see the official data with my own eyes and get a chance to learn and experience the method of analysis. And it is even better that I got a chance to review and apply what I have learned in the bio-statistics course, which is perfect timing for practice. Thank you so much!
・このようなデータの二次利用ができるということ、利用するまでの手順など含めて勉強になりました。今後機会があれば利用したいと思いましたが、リサンプリング等でサンプル数が少なくなること、地域情報が削除されることなど限界もあるように感じました。自身の研究では教科書での勉強と先生・先輩から少しずつ教えてもらって何となく進めている状況ですので、解析のやり方を体系的に教えていただけたこともとても勉強になりました。ありがとうございました。
・本日はありがとうございました。JMPを使う練習にもなりとてもよい機会になりました。今回は限られた変数のみの解析でしたが、変数の組み合わせを変えて他の分析もしてみたいなと思いました。
・JMPを使っての解析は初めてでしたのでとても勉強になりました。少し難しく感じたので今後勉強していきたいと思います。
・多岐にわたる項目がありおもしろかったです。
・これまで国民生活基礎調査のデータを取り扱ったことはなく、普段自身で解析対象としているいくつかのデータとは変数その他の特徴も異なり新鮮で非常に貴重な経験となりました。私がこれまで解析したデータの中には変数名一覧の整理が不十分だと感じるデータもありましたが、本データの解析にあたっては、B符号表で変数の内容が一覧できるように整理されており、本データを解析するうえで障害なく進められたのは本表の貢献が大きいと感じております。また、調査項目が多岐にわたること及び「仕送りの状況」といった特色のある情報が調査項目に含まれていることに関心いたしました。一方、項目ごとに情報の粒度がばらついている印象があり、例えば、「学校の種類」については、単に「大学院」とするよりも「専門職大学院」と「大学院」や「修士課程」と「博士課程」のようなより粒度の区分がなされているほうが、より利活用の助けになるのではないかと考えました。これは、大学院生の実感として修士課程で卒業する学生と、博士課程に進学する学生では特性に大きな隔たりがあると感じているからです。
・実際のデータを用いて実習を行うことで、国民生活期調査では、どのようなデータを収集することができ、どのように扱う必要があるか、を知ることができた。一方で、今回の扱ったデータは調査票形式になっており、比較的扱いやすいデータのように感じたが、医薬品のデータ、レセプトデータなどのその他のデータに関しては、おそらくもっと複雑なのだろうと思った。実際に解析を行う際、例えば総所得など一つの項目に対して、膨大な種類のデータがある場合、どのように層別して解析をしていくのか、根拠に基づいて決めていく必要があると感じた。ありがとうございました。
・公的なデータを実際に自分の手で見たりする機会は初めてだったので貴重な経験になりました。まずデータの解析までに適切な形に整えないといけないことを改めて感じました。特に、列名がなかったことは驚きで授業では列名の挿入までの流れがスライドに示していただいたのでスムーズにいったが、自分がいきなりこのデータを渡されるだけだとまずそこで苦戦しそうだと感じました。
・国民生活基礎調査の匿名データを実際に使って解析する貴重な機会で、とても勉強になりました。公的データの利活用で何ができるのか、その一端を具体的に実践的に知ることができ、今後の研究等に活かすことをイメージすることができました。ありがとうございました。
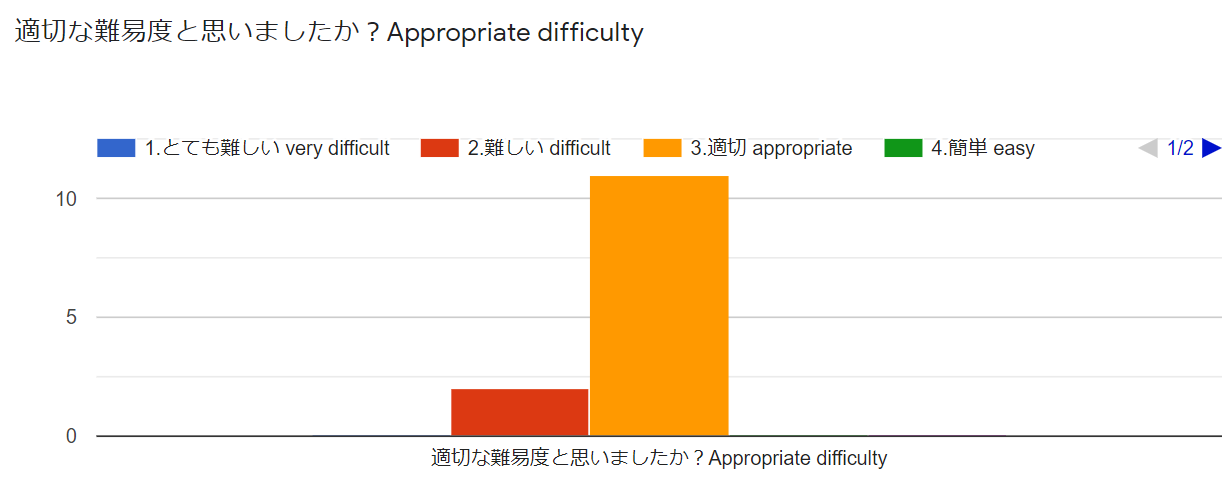
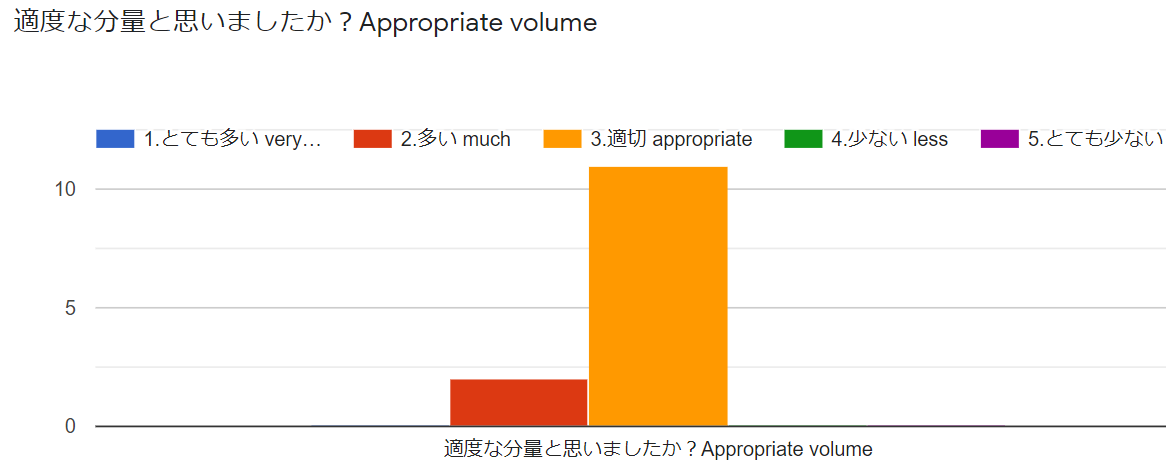
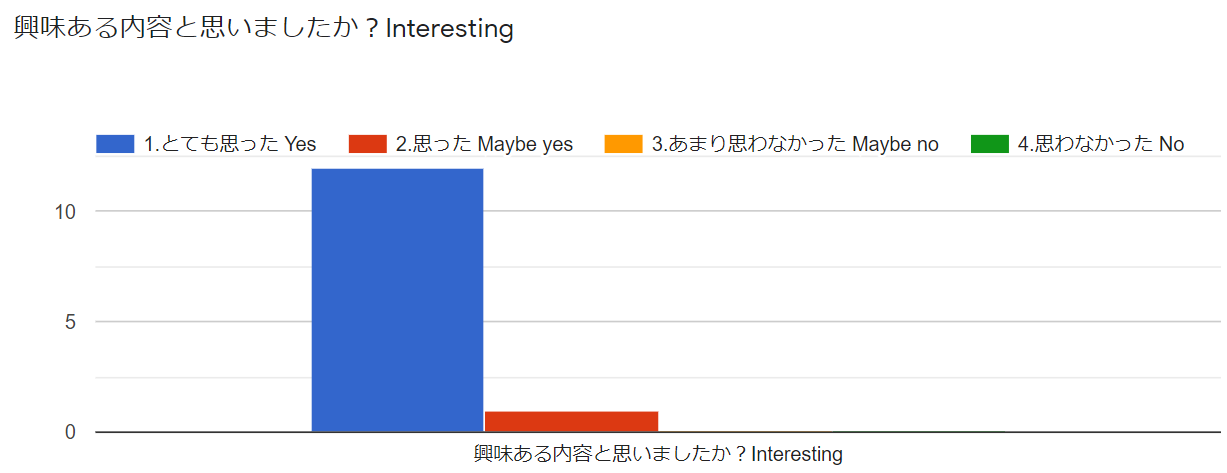
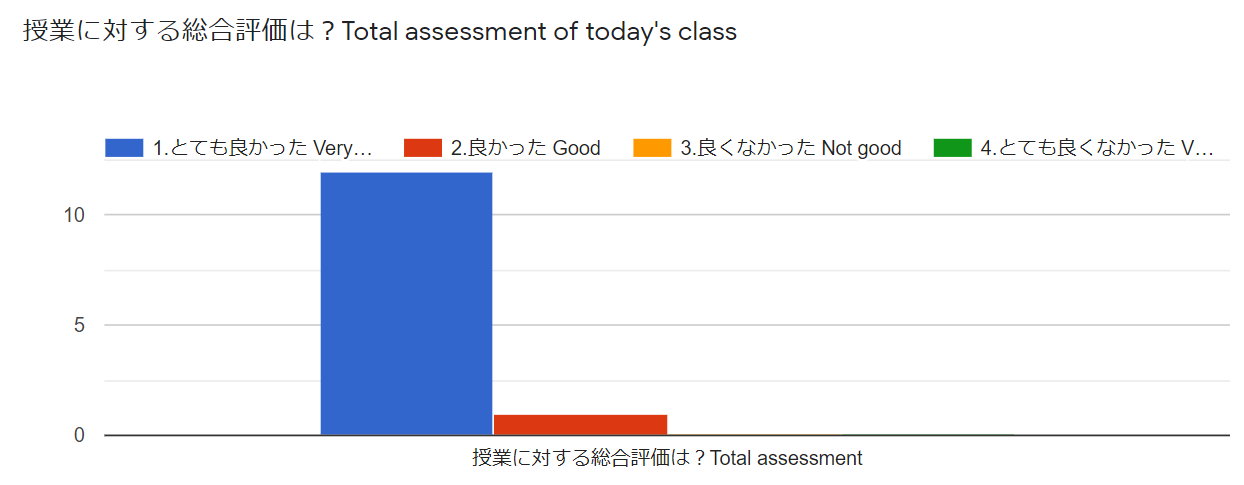
以上